|
如果手头没有GPU资源是没法很好进行学习和实操各种深度学习模型的,所幸有一些平台提供了GPU资源供广大兴趣爱好者进行免费使用。 一、免费GPU资源的平台 1. Google Colab地址:https://colab.research.google.com/ 简介:Google Colab(全称Google Colaboratory)是由Google提供的一种基于云端的交互式编程环境,特别适用于机器学习、数据分析和教育目的。 GPU:支持jupyter notebook直接运行,提供的最长执行时间为 12 小时,其中空闲时间为 30 分钟,显存大小大概在15GB左右, 免费的google 磁盘大概在15GB左右时不时断线,不稳定。 2. Kaggle地址:https://www.kaggle.com/ 简介:Kaggle是一个全球性的数据科学和机器学习竞赛平台,汇聚了全球顶尖的数据科学家和机器学习爱好者,共同解决各种实际问题,分享知识和经验。 GPU:支持jupyter notebook直接运行,每周30个小时,显存大小大概在15GB左右, 免费访问的 GPU 为 Nvidia Tesla P100 和 T4,单次会话最长运行时间为 9 小时,相对 colab稳定一点。 3. 阿里云(PAI系列)地址:https://free.aliyun.com/?searchKey=PAI 简介:PAI(Platform of Artificial Intelligence)人工智能平台面向企业客户及开发者,提供轻量化、高性价比的云原生人工智能,涵盖DSW交互式建模、Designer拖拽式可视化建模、DLC分布式训练到EAS模型在线部署的全流程。 GPU:支持控制台和jupyter notebook, 三个月的试用期,免费版本显存一般是16G左右,无对话时间限制, 建议不用的时候,关掉实例,毕竟除了时间还有资源大小限制。 4. 阿里天池地址:https://tianchi.aliyun.com/ 简介:阿里天池的天池实验室,通常也称为阿里天池云服务器或天池实训平台,是阿里巴巴集团旗下的阿里云专门为数据科学家、开发者、科研工作者及学生等群体打造的一个云端开发与实验平台。 GPU:选择“天池实验室”-->“天池Notebook”进入,然后注册,登录。这是阿里云提供的打比赛的平台。总共 60小时的免费GPU使用,CPU不限量,但是单次使用GPU最多8小时。 由于某些原因Google Colab不一定能正常访问,阿里云(PAI系列)和阿里天池有试用期到期的说法,综合对比,Kaggle可以正常打开使用,每周又有30小时的免费时长,相对来说是非常适合进行深度学习跑模型的。 二、Kaggle平台介绍我们在开始Kaggle平台的注册前,再进一步了解下Kaggle平台。 Kaggle是一个国际知名的数据科学和机器学习竞赛平台,由Anthony Goldbloom和Ben Hamner于2010年在墨尔本创立。该平台最初是为了让数据科学家参与各种竞赛,并与其他人竞争。随着时间的推移,Kaggle逐渐发展成为一个更大的社区,提供了更多的功能和资源,以满足数据科学家的需求。在2017年,Kaggle被Google收购,并成为Google Cloud的一部分。Google此举旨在提升其在数据科学和机器学习领域的影响力,并扩大Google Cloud业务。 Kaggle的优点提炼:
竞赛丰富:Kaggle举办各类数据科学竞赛,涵盖表格数据、计算机视觉、自然语言处理、语音处理和生物医学等多个领域。这些竞赛通常由各大企业和研究机构赞助,提出具体的数据问题,参赛者需要开发出模型来解决这些问题。这些竞赛不仅推动了数据科学领域的研究,还为企业寻找创新解决方案提供了机会。
数据资源丰富:Kaggle提供了大量的公开数据集,用户可以自由地浏览和使用这些数据集,以训练模型或进行数据分析。这些数据集来自各种来源,包括公共数据集、商业数据集和竞赛数据集。此外,Kaggle还提供了一个数据集市场,用户可以购买和销售自己的数据集。
社区活跃:Kaggle是一个活跃的社区,用户可以在这里分享他们的代码、模型和项目,与其他数据科学家交流和合作。用户还可以对代码和模型进行评论和评分,以提供反馈和支持。这种社区氛围有助于用户学习和提升技能,同时也促进了数据科学领域的发展。
学习和提升机会:Kaggle为数据科学家、机器学习工程师和学生提供了一个展现和提升技能的大舞台。通过参与各类竞赛,用户可以与其他参赛者一决高下,提升自己的数据科学技能。对于新手来说,Kaggle还提供了许多入门级别的竞赛和学习资源,帮助他们逐步熟悉Kaggle的操作方式和提升技能。
求职机会:Kaggle不仅是一个学习和提升技能的平台,还是一个展示个人才能和寻找工作机会的舞台。参与Kaggle竞赛并取得优异成绩的用户,无疑能为个人简历增添亮点,有助于在数据科学和机器学习领域的求职。尽管Kaggle在2014至2022年间设有专门的招聘板块,但即使后来该板块关闭,Kaggle仍通过其他途径帮助用户发掘数据科学领域的工作机会。 三、Kaggle平台的注册我们打开Kaggle官网(https://www.kaggle.com/),点击右上角的Register按钮,注册账号。
如果没有google邮箱,我们可以使用普通邮件进行注册:
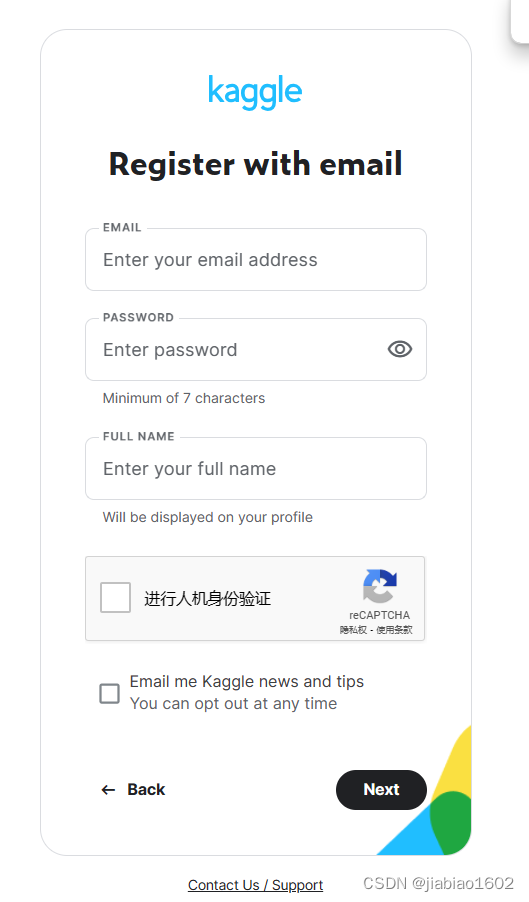
在注册界面,您需要填写您的邮箱地址和用户名,并设置一个安全的密码。请记住这个密码,因为之后每次登录都需要用到它。填写完相关信息后,点击Next进入下一步操作。
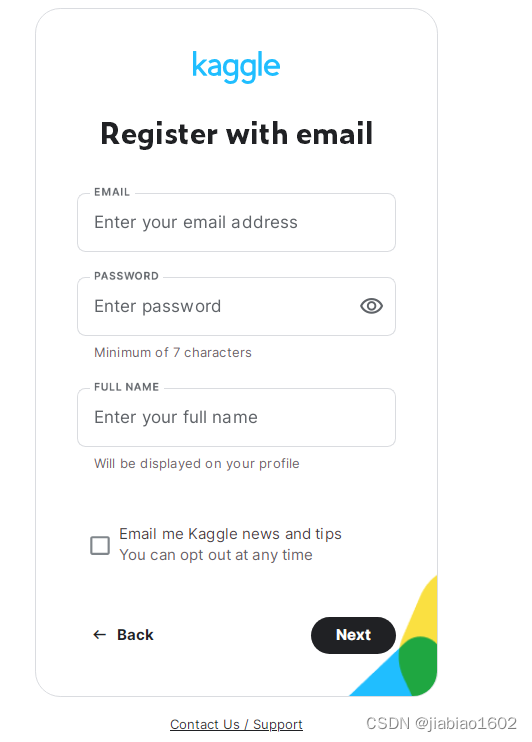
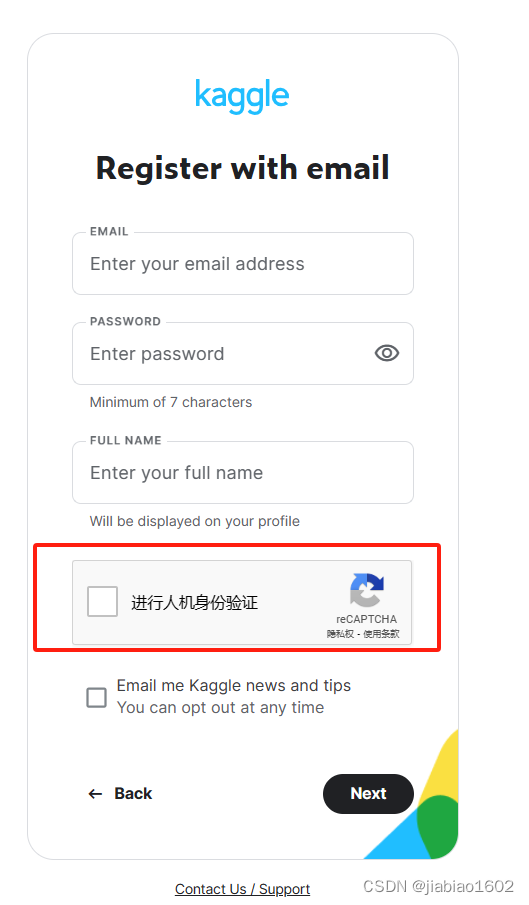
这里需要注意,在注册Kaggle用户时,往往出现不了人机验证从而导致无法完成注册。有不少人出现的注册界面如下:
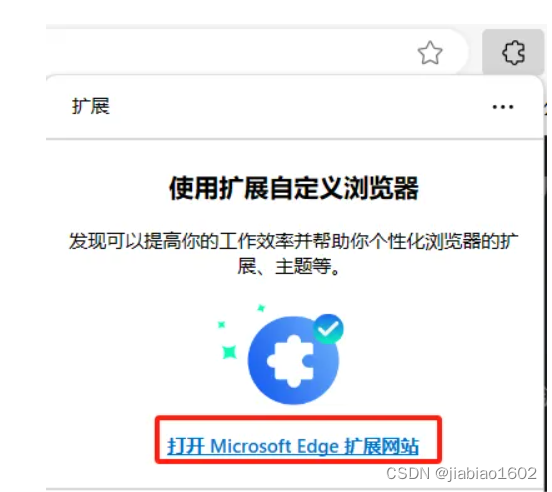
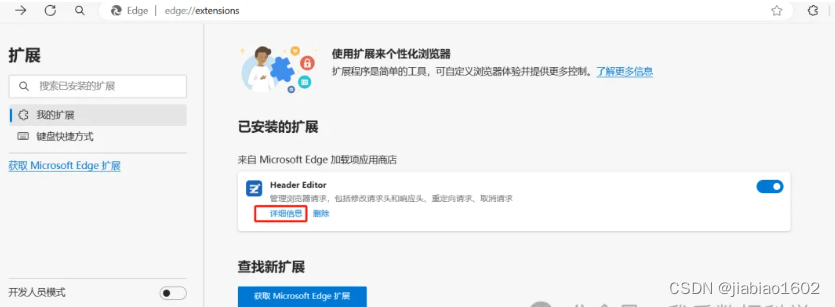
们可以通过在Google或Edge安装对应的插件后再刷新注册界面即可。 接下来以Edge浏览器为例带领大家如何完成Kaggle账号的注册。 我们点击右上角...,找到扩展并点击,在弹窗中点击 打开Microsoft Edge扩展网站:
在Edge加载项的左上角搜索框输入:Header Editor,搜索该插件。
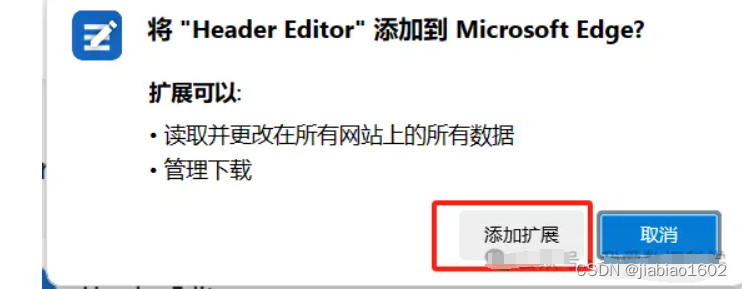
点击第一个的获取后将出现如下弹窗,我们点击 添加扩展。
添加后将出现如下弹窗:
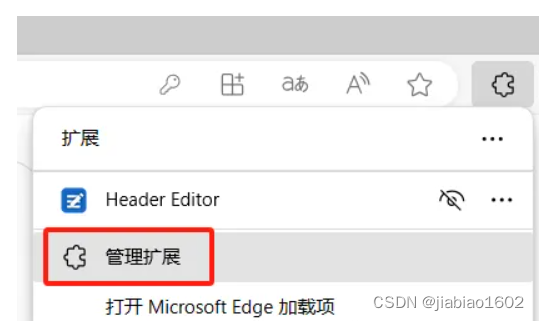
接下来在右上角点击 扩展图标,点击管理扩展:
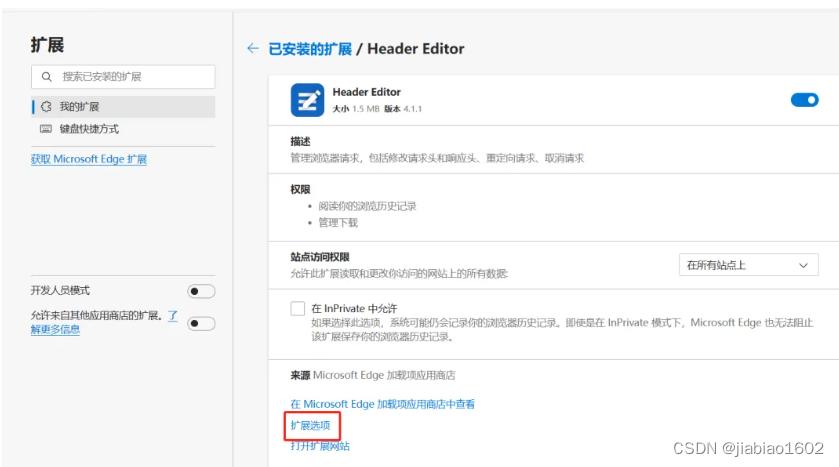
点击Header Editor扩展的详细信息:
点击扩展选项:
点击导入导出:
在下载规则URL中输入:https://azurezeng.github.io/static/HE-GoogleRedirect.json后点击下载。
下载后点击保存。
保存后将出现导入成功的提示。
我们在Edge浏览器再次刷新Kaggle的注册页面,将出现人机交互的内容了。
大家再次按照提示操作即可完成Kaggle的账号注册。 四、Kaggle平台的登录注册完成后,我们点击右上角的Sign In,即可进入登录页面:
在登录页面输入刚刚注册好的账号密码即可登录Kaggle平台了。
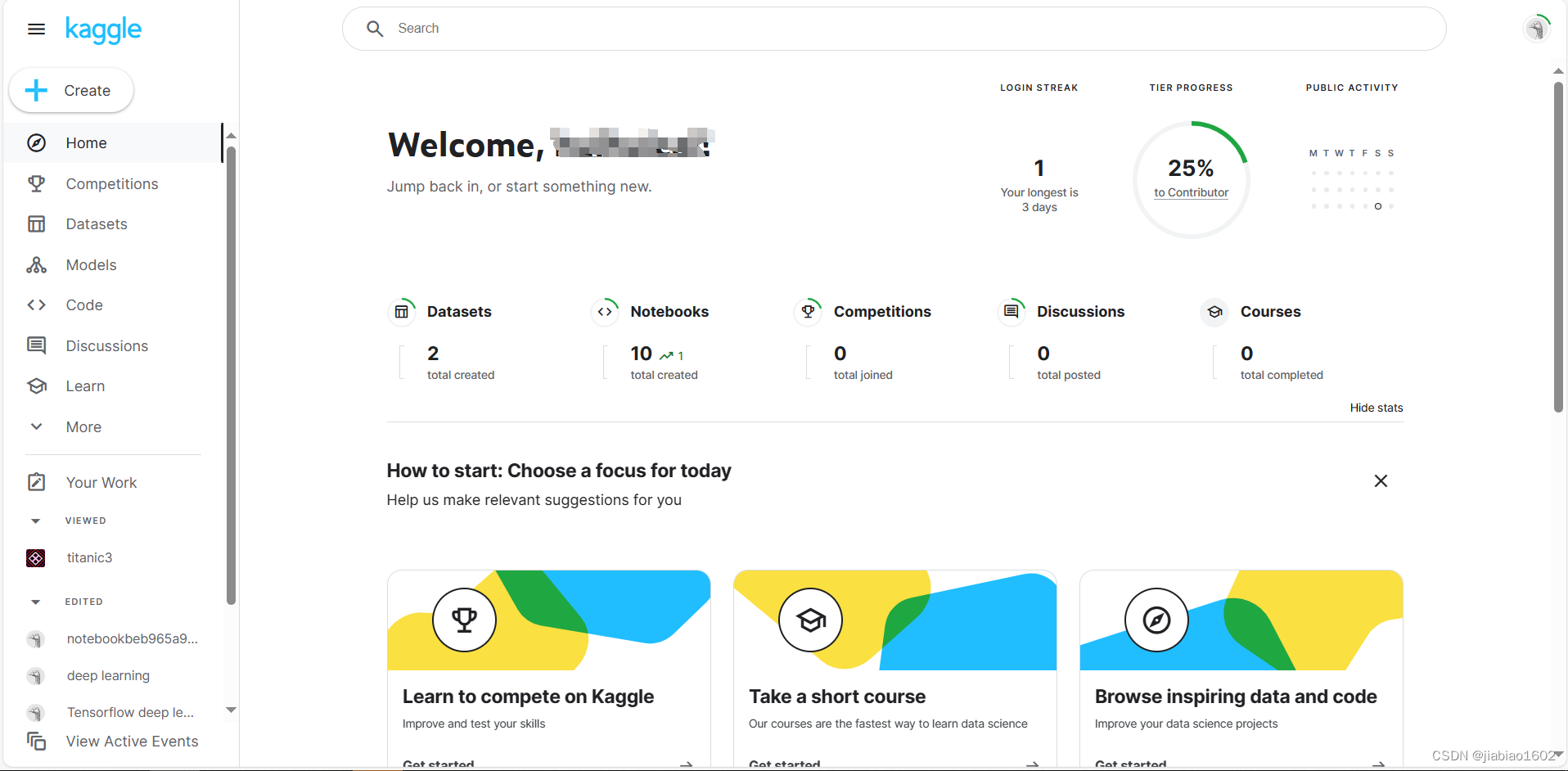
登录进去后,点击右上角的头像:
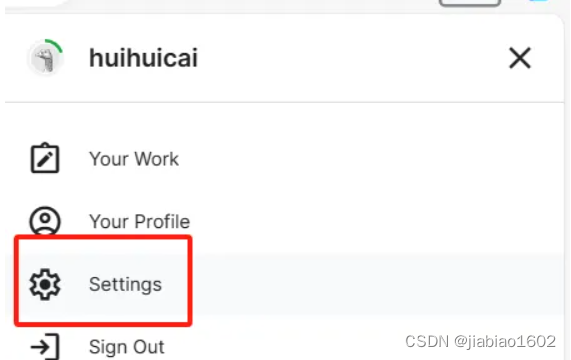
点击Setting进去,即可查看账号的各项信息。
果想要使用GPU,需要进行手机验证。
验证后,即可查看每周可使用的GPU时长了。
点击左上角的+号,点击New Notebook即可创建新的Jupyter Notebook:
Jupyter Notebook默认是使用Python,可以在左侧的Language切换为R。
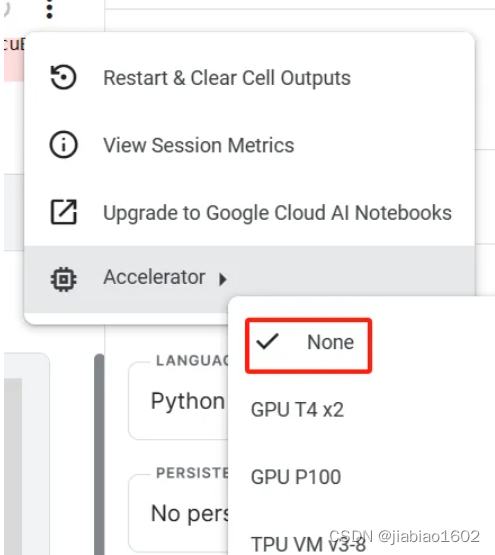
Notebook默认是未使用GPU资源的,可以通过Notebook右上角的Accelerator进行切换。
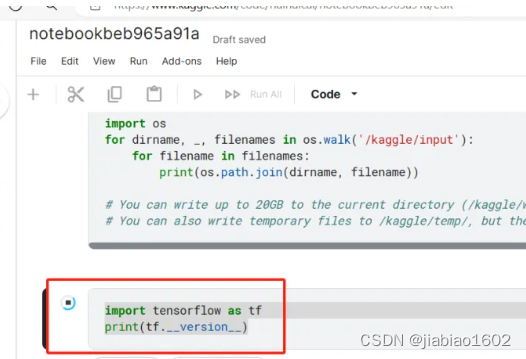
Notebook已经帮我们安装好了TensorFlow及Pytorch等深度学习框架。我们先不进行资源切换,在新单元格中输入以下代码,导入并查看TensorFlow的版本。 import tensorflow as tf print(tf.__version__)
此时使用的是TensorFlow 2.15.0的版本。 接着,我们在单元格中输入以下代码,查看是否使用GPU。 print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
输出结果为0,表示无可使用的GPU。 下一步,我们将资源切换为GPU T4*2。
在弹窗中点击 Turn on GPU T4*2,进行资源切换。
再重新运行下一下命令,将重新启动session:
我们在重新运行以下命令查看可用的GPU数量: print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
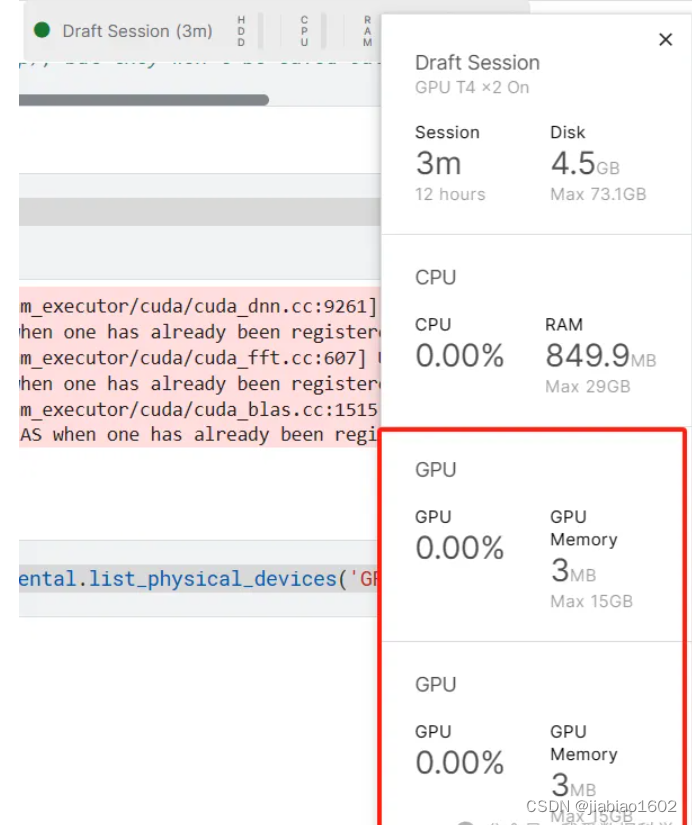
输出为2,说明有可用GPU。 我们也可以鼠标点击右上边,查看可用的资源情况。
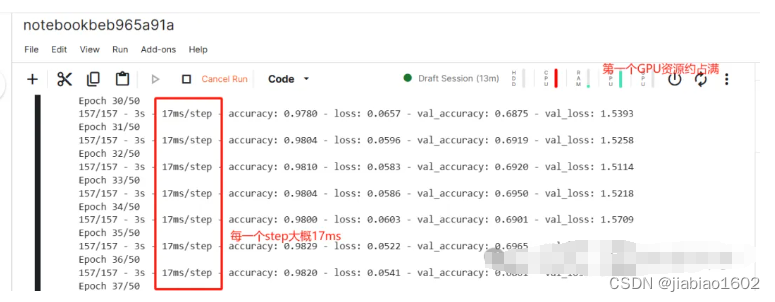
可见,给的资源还是很给力的。 六、Kaggle平台跑深度学习接下来,让我们在Kaggle平台上跑《深度学习从入门到精通:基于Keras》(微课版,谢佳标著)书中第四章(4.4 案例实训:对 CIFAR-10 数据集进行图像识别)的卷积神经网络的例子。 数据导入、处理、建模及训练的代码如下: import tensorflow as tf from tensorflow.keras import layers, models import matplotlib.pyplot as plt cifar10 = tf.keras.datasets.cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data() # 图像数据标准化 x_train = x_train.astype('float32') / 255.0 x_test = x_test.astype('float32') / 255.0 # 标签数据one-hot编码 num_classes = 10 y_train = tf.keras.utils.to_categorical(y_train, num_classes) y_test = tf.keras.utils.to_categorical(y_test, num_classes) # 构建简单卷积神经网络识别CIFAR-10图像 # 构建模型 model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3))) model.add(layers.Dropout(0.2)) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Dropout(0.2)) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dropout(0.2)) model.add(layers.Dense(10,activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy']) # 模型训练 history = model.fit(x_train,y_train,epochs=50,batch_size=256,validation_split=0.2,verbose=2)我们先用GPU T4*2的资源跑该深度学习模型,查看训练模型的耗时情况。
训练的每一个step大概耗时17ms,速度是相当可以的。 最后,让我们再次将资源切换为None,查看此时跑深度学习模型的情况。
此时,仅仅利用CPU跑的深度学习模型每一个step都耗时在600ms以上,效率远不如GPU。 自此,我们已经学会了如何在kaggle上注册及使用GPU资源。Kaggle还可以上传我们本地的或Kaggle平台的数据和Jupyter Notebook文件,后续再展开介绍。 好了,关于如何申请和使用Kaggle平台的GPU资源我们就分享到这里,如果大家对想学习其他更多内容,包括ChatGPT大模型、数据挖掘、可视化、R语言、Python等专题,可关注“我爱数据科学”的公众号或视频号。 我爱数据科学公众号二维码:
如果公众号二维码过期,可在 微信 -> 公众号 -> + -> 搜索 “我爱数据科学” 进行关注。 我爱数据科学的视频号二维码:
|